

I have seen a couple of presentations that use plots of PubMed query results. I have even seen some of them in papers. I just think it’s really cool, so I wanted to play with something that could provide the data.
A couple of google searches lead me into two nice options to do this in R.
RISmedpackage, see CRAN or Dave Tang’s Blog- A custom approach from Kristoffer Magnusson
I went with the custom approach, decided to borrow heavily from Kristoffer’s repo, and did a few modifications here and there. Mainly, I updated libraries, included some dplyr output to make it cleaner, and separated functions into several files.
You can find the updated code in the following repo:
https://github.com/matiasandina/pubmed_query
The logic of the code is to loop over the search terms and the years, performing queries to PubMed each time. To make things more friendly we wrap everything into a main function that performs some checks and handles the multiple calls to the working functions. This main function, query_pubmed(), expects a query (character vector), and 2 years for the time interval (yrStart and yrMax).
The function is somewhat self contained, if it can’t find things on the local computer it will source from GitHub1. Here’s a little demo of the main function query_pubmed(). Since we are using internet to get the data, I assume the user will be able to source from GitHub (these calls are often performed via devtools::source_url).
Little demo
Let’s look for the term hiv in publications from the 1970 until today. PubMed requests us to limit the traffic to ~3 queries per second. Thus, queries will take a while because the function has Sys.sleep(0.5) in between iterations. You will see a progress bar for each term (not shown here for simplicity).
I chose to keep the graphic output as simple as possible (aka use ggplot2 defaults) and return a data.frame that can be fed into a custom ggplot2 call later, if the users feel like it. Here’s a glimpse of the returned object.
query_term year count total_count freq
1 hiv 1970 1 219426 0.0004557345
2 hiv 1971 0 223658 0.0000000000
3 hiv 1972 0 227949 0.0000000000
4 hiv 1973 0 231159 0.0000000000
5 hiv 1974 0 235136 0.0000000000
6 hiv 1975 1 249241 0.0004012181Making things faster
Total publication numbers should not change2. Thus, if we don’t want to waste time grabbing the total number of publications over and over, we can either:
- Use
get_totals() - Get it from GitHub
I will do my best, but I can’t be certain I will keep running the function and pushing once a year to GitHub (as in forever)3. I don’t feel like waiting, I already have a recent version in the repo.
Having this object around will speed the main function (it will not query PubMed every year for the totals). Here’s a graph of the number of publications by year:

Multiple terms
We can use multiple terms to query, just make a character vector. For example, let’s add aids and hepatitis b:
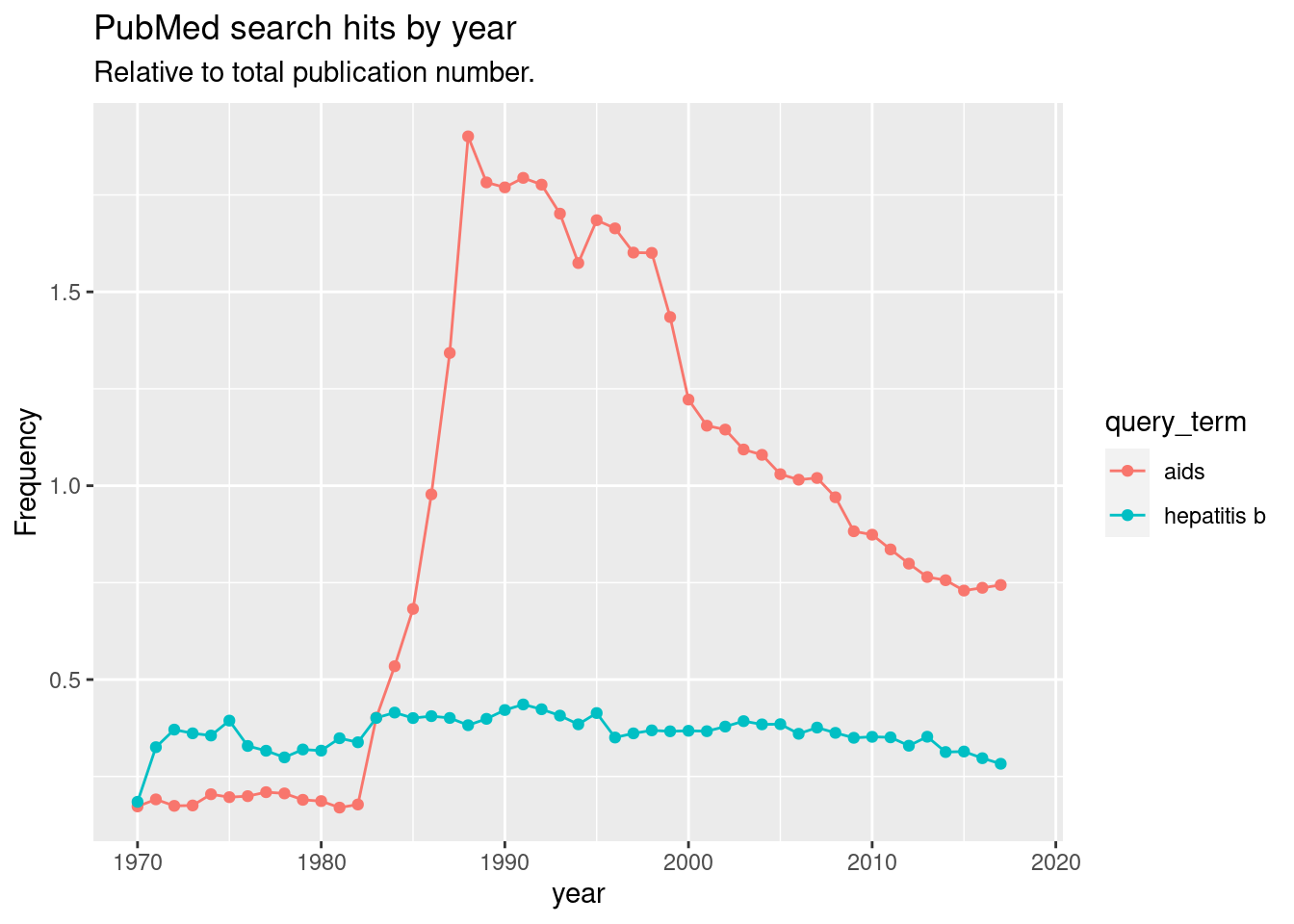
Because we saved the previous object in the environment, we don’t have to query again, we can merge the data and plot all together.
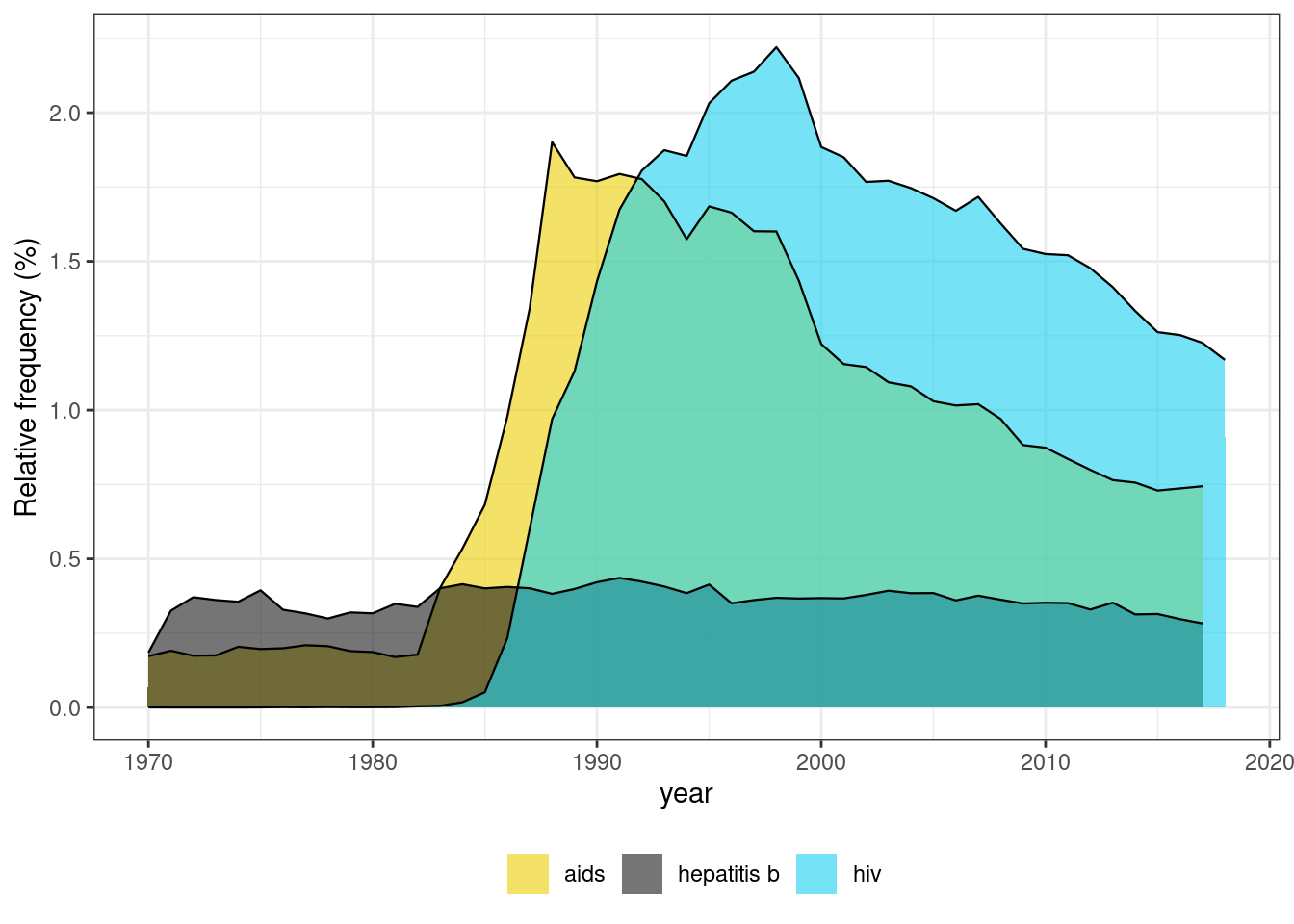
We see that the term aids came first in the literature, before the virus was identified, in the early 1980s. Although strongly correlated with aids, hiv is a term with higher frequency. Research for hepatitis b seems to have kept a constant relative level, growing as much as the total body of research.
Footnotes
Granted, several packages are needed to run the code. I assume users will know how to
install.packages(...)if in need.↩︎There are some variations in the recent years as the data base updates, but shouldn’t be significant for these purposes.↩︎
Yes, I guess I could automate it but reaching diminishing returns here…↩︎
Reuse
Citation
BibTeX citation:
@online{andina2018,
author = {Andina, Matias},
title = {Query {Pubmed} in {R}},
date = {2018-11-23},
url = {https://matiasandina.com/posts/2018-11-23-query-pubmed-in-r},
langid = {en}
}
For attribution, please cite this work as:
Andina, Matias. 2018. “Query Pubmed in R.” November 23,
2018. https://matiasandina.com/posts/2018-11-23-query-pubmed-in-r.